When you ask an LLM without web search enabled a question like “What happened in the news this morning?”, the LLM will respond by telling you that it doesn’t have access to current events and suggest you check a more current news source such as Reuters or Google News.
Conversely, ask an LLM with web search enabled the same question, and you receive a detailed rundown of breaking stories, political controversies, and sports news from the past 24 hours.
Identical question. Same underlying technology. Completely different answers. The difference isn’t that one model is smarter or more current than the other. The difference is whether web search was triggered.
But why does that matter? Both models were trained months ago. Their internal knowledge stopped updating the moment training ended. So how does flipping a switch allow one model to suddenly “know” what happened this morning? The answer reveals a fundamental distinction most users never consider: the difference between what a model learned and what a model read.
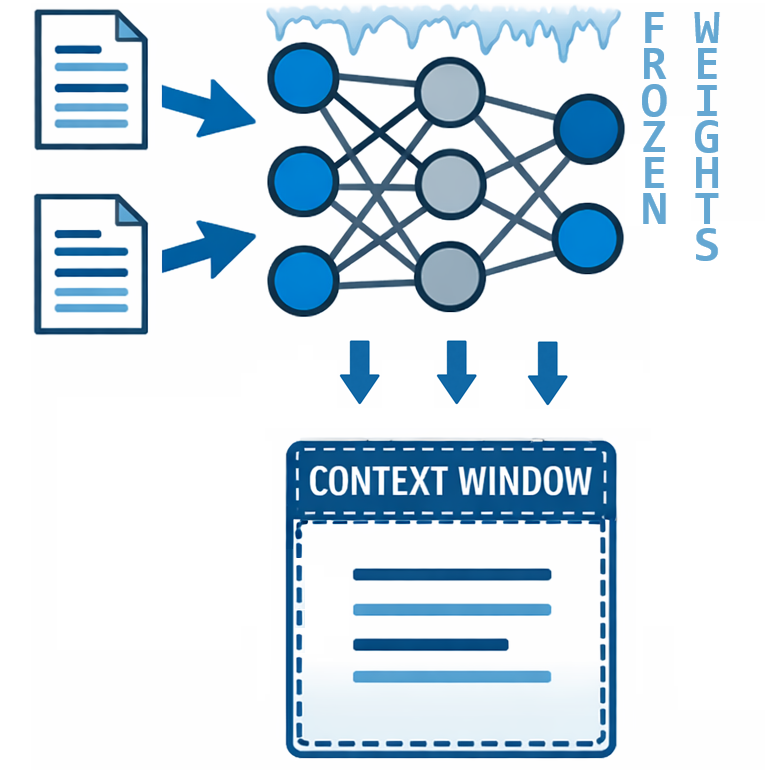
LLMs don’t update their weights (the billions of numerical parameters that encode everything learned during training) when you chat with them. They don’t learn from your conversations. But they can access external information and reason over it within their context window. This isn’t learning; it’s reading. And understanding that difference changes how you think about what these systems can and cannot do.
“A model with web search doesn’t know more. It can see more. The knowledge lives in the retrieved text, not in the weights.”