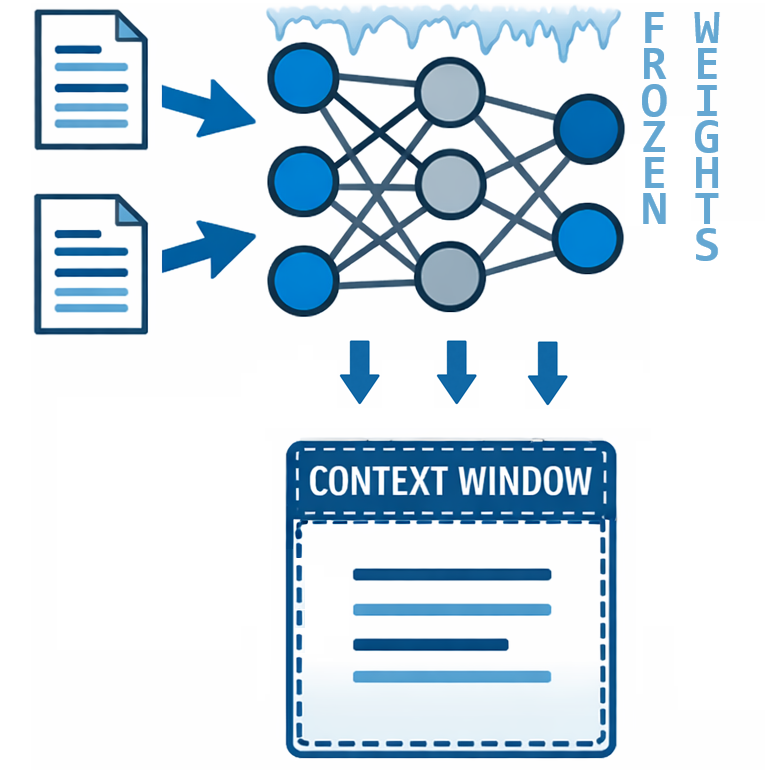
A recent LinkedIn post from Michael Palmer described how discrete mathematics is the foundation for how computers reason about problems. That thread got me thinking about just how many discrete math concepts show up inside systems that seem purely statistical. LLMs are often described in terms of neural networks, gradient descent, and probability distributions. If you’ve taken discrete mathematics and wondered what it has to do with modern AI, the answer is: more than you’d expect.
Underneath the calculus and linear algebra, the same structures you learn in a discrete math course keep appearing: sets, predicate logic, Boolean operations, modular arithmetic, formal proof patterns. This post traces those connections.
“Attention heads act like soft predicates over tokens. Masks are set operations. Chain-of-thought resembles proof structure.”